Launching Scalabitz
Today marks the launch of my lingering weekend-project: scalabitz.com. It tries to surface interesting Scala content through the API of link-shortener Bit.ly. The site was built using Scala and Play (and a bit of Akka) with a MongoDB storage layer and can be found on GitHub.
![]()
Before you read on you may want to take a look at scalabitz.com to get an idea what the rest of this post is all about. You can also follow Scalabitz on Twitter.
Finding content
One of the harder problems on the web is how to find relevant content. Link aggregators like Reddit and Hacker News solve part of this problem by crowd-sourcing links. Twitter and Facebook can be more tailored, but only work as good as the people you follow. Startups like Prismatic create a more personalized solution using machine learning and there are many solutions combining different approaches. In short, this is not a solved problem. A while ago I stumbled across the Bit.ly API and wondered whether it could provide an alternative. Can we find interesting content from the data behind a link-shortening service? Hence the start of my experiment. So far I believe the answer is a cautious yes, since people tend to shorten links they care about.
But is it relevant?
The Bit.ly API offers a search endpoint. If you start feeding it 'Scala' as keyword, surprisingly many interesting Scala-related links surface. But this also gives a lot of false positives. For example, it turns out there are many clubs and restaurants called 'Scala' announcing events through Bit.ly links. You could use 'Scala programming' as search phrase, but then you miss a lot of content.
For scalabitz.com I went with just 'Scala' as search phrase. This means I have to do something about the false positives. Currently, the results on the frontpage are manually curated. There is a small keyword-matching heuristic on content that helps me to quickly see whether content is relevant:
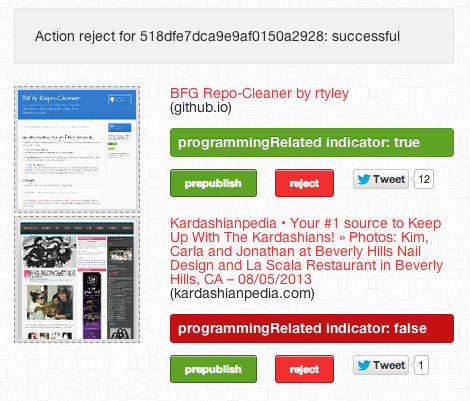
(a partial screenshot of the admin page, green is good, red is bad...)
Fortunately the volume of new links discovered through the Bit.ly API is manageable for now. To avoid flooding the frontpage after a moderating session by yours truly, approved links are released one-by-one in a timed fashion. Hence the 'prepublish' action on the screenshot above, which puts the link into the publishing queue. Obviously, this is all far for from perfect. My goal is to make the curation process fully automatic. As a next step I will try to implement a supervised machine learning algorithm when I have a larger corpus of training data with correct publish/reject decisions available.
Additionally, a different Bit.ly endpoint provides data on how many click-throughs the links received. This count is updated periodically by the Scalabitz backend and shown on the frontpage.
Why Play?
One of the reasons I chose the Play framework was that I wanted to explore building a webapp that is completely asynchronous and non-blocking. Play helps you to write reactive applications on all levels: from handling HTTP requests, to performing the backend REST calls and querying the database. The first two are native Play features and for the latter you can use the ReactiveMongo driver. Even though the driver is not at 1.0 yet, it is a pleasure to use.
The main building block for this application is scala.concurrent.Future. Introduced in Scala 2.10, the Future API provides a very nice way to do async programming. It has been adopted by both Play and Akka, so all the pieces fit together perfectly. To give a taste of how easily you can do non-blocking and asynchronous programming with Scala and Play, consider the following snippet:
ScalabitzService.getPublishedArticles(0, Some(100)).flatMap { articles =>
val clickFutures = for(article <-articles) yield clickWSCall(article)
Future.sequence(clickFutures)
}
(see the code in context on GitHub)
The getPublishedArticles method returns a Future[List[ScalabitzArticle]], essentially promising that this list of articles will be available from Mongo at some point in the future. Next we must specify what should happen to the result inside the Future when it is succesfully completed. We can do this by defining a transformation, in this case using the flatMap method. In fact, flatMap is a monadic bind operation, making it a general mechanism for composing actions with other Futures like we are going to do here.
On to the actual transformation. For each of the articles we want to retrieve the click count. Since there is no single Bit.ly endpoint accepting multiple identifiers at once, we need to do a single call to Bit.ly for each article. Obviously we don't want to do this blocking and sequentially. Therefore, the for-comprehension builds up a List[Future[(String, Int)]] based on the articles we got from the outer database call. The method clickWSCall uses Play's non-blocking WS API to perform these calls, ultimately returning a Future. Now the variable clickFutures represents the result of all these calls at some point in the future. However, there's no blocking or busy waiting for any WS call. Then, we feed the resulting list of type List[Future[(String, Int)]] to the Future.sequence method. Et voila, this creates a new Future[List[(String,Int)]] (notice the inversion in the type?), eventually containing all click counts associated with their id in a tuple. It is asynchronously completed when all individual futures are completed automatically.
The topic of reactive applications deserves a blogpost of its own, which will surely follow... After some adjustments the paradigm feels almost as natural as doing it the 'old way'. Almost, with the exception of error handling, which I haven't really tackled in an elegant manner yet. Another area of improvement is to find a nice model for dependency injection of services (may be the Cake pattern?), currently there's just singleton objects wired directly to each other.
Deployment
I've had many toy-projects over the past years, but none of them made it out of the comfort of my own machine. Therefore I'm still looking for the perfect production environment. Heroku is the current deployment platform for Scalabitz because it supports Play apps natively, is low-friction and it's free. Deploying the app is as simple as doing a Git push to Heroku, which is nice. Since the app is rebuilt on Heroku before it is deployed and started, it is a bit slower than ideal. Also, I'm not sure how long the free tier will work for this application. I guess I will find out soon enough.
Future developments
Next up is automatically feeding the @scalabitz twitter account with published links. So Follow @@scalabitz to get a nice feed of Scala articles! On the backend side of things the next priority is to get a more accurate classification of incoming links. Fortunately I've been notching up my machine learning skills in the past year, so that should be a nice challenge. One other interesting idea is to generalize this 'platform', since the same could be done not just for Scala but for a range of topics.
In short, I have tons of ideas for developing Scalabitz further. But the most important question is: what do you think? Promising? Pointless? Let me know in the comments or on Twitter!





